I had to do some work fixing replication and wanted to share the experiences.
Short:
- MariaDB is getting new storage engines that share the data between MariaDB
instances - There is a demand to run these “shared-disk” engines alongside regular
engines and replication. Like so:
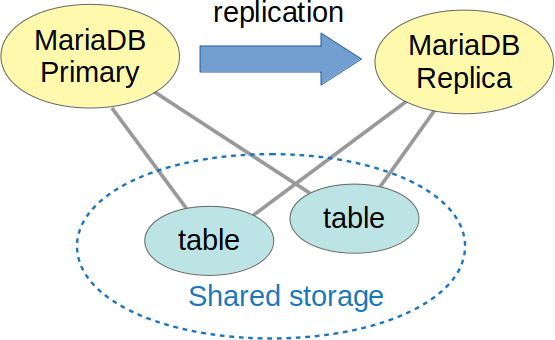
- Replication breaks when some tables have changes from the primary (aka master) “automagically” appear on the replica (aka slave).
- MariaDB is getting support for running “shared disk” engines alongside with replication. The user experience is not entirely seamless yet, but it’s getting better.
Longer:
MariaDB is getting new storage engines:
The first one is S3 Storage Engine, available in MariaDB 10.5. It’s basically a read-only Aria table that is stored in Amazon S3 or a compatible service. Its target use case is archive data that doesn’t get read much, and cloud environment where local storage is pay-per-gigabyte. In this setting, it pays off to put the archive into an S3 bucket and then share it between all MariaDB instances you have. Note that only the archive is shared, for non-archive data you’ll still want replication.
The second new engine is the Xpand Storage Engine. It is only available in MariaDB Enterprise. It connects to Xpand cluster (formerly known as Clustrix). Xpand cluster is a clustered database targeting mostly OLTP workloads. Think NDB Cluster which can also speak SQL.
If you’re just using Xpand, you don’t need replication:
- All MariaDB nodes in the cluster immediately see all data
- As for table definitions, Table Discovery feature allows one MariaDB instance to learn about the tables created through other MariaDB instances.
But it turns out there’s a demand to still have replication enabled. It’s used for hybrid Xpand-and- InnoDB setups, for propagating MariaDB-level entities like VIEWs, etc.
The problem
The base problem: when the replica (slave) starts to apply changes to the shared table, the data is already there. Moreover, if the replica has a delay, then the primary (master) might have already made further updates to it. Applying older updates from binlog will undo them and/or cause errors.
Also, we cannot binlog any statements that read the shared tables, as the data might be no longer there when the replica will be applying the statement. This includes e.g. statements like “ALTER TABLE xpand_table ENGINE=InnoDB”.
The solution
I think, the ideal would be to have a primary-only solution where the binlog is not allowed to have any references to the shared tables. But this wasn’t the choice made. As far as I understand, Monty wanted the binlog to be also usable as a self-contained backup. As a consequence, one needs to have special behavior both on the primary and on the replica.
Settings on the primary (master). Settings for S3 are on the left, Xpand settings are on the right:
| s3_replicate_alter_as_create_select=1 | xpand_replicate_alter_as_create_select=1 xpand_master_skip_dml_binlog=1 |
Settings for the replica (slave):
| s3_slave_ignore_updates=1 | xpand_slave_ignore_ddl=1 |
Unfortunately, the solution is not complete. One needs to be careful when creating table in one engine and then changing it to another. This can confuse a delayed replica: MDEV-24351, MDEV-24367.
But if one is careful, things seem to work. As it usually is with replication :-).
