Three days ago I’ve finally managed to push the code for WL#3985 “Subquery optimization: smart choice between semi-join and materialization” into MySQL 6.0. I missed the clone-off date so it won’t be in the upcoming MySQL 6.0.9 release, the only way to get it before the next 6.0.10 release is from the lp:mysql-server/6.0 bazaar repository.
What’s new in the push
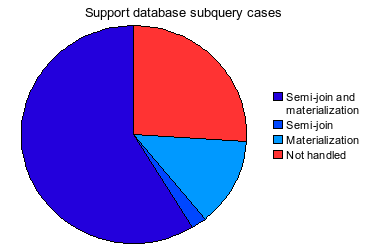
Before WL#3985, 6.0’s subquery optimization had these three deficiencies:
- For semi-join (see cheatsheet for definition) subqueries, you had to make a choice between having the optimizer use materialization or all other strategies. The default behavior was not to use materialization, you could only get it by setting a server variable to disable all other strategies.
- The choice among other strategies (FirstMatch, DuplicateWeedout, LooseScan) wasn’t very intelligent – roughly speaking, the optimizer would first pick a join order as if there were only inner joins, and then remember that some of them are actually semi-joins and try to find how it can resolve semi-joins with the picked join order.
- Materialization only worked in the outer-to-inner fashion, that is, if you got a query like
select * from people where name in (select owner from aircraft)it would still scan the people and make lookups into a temporary table of aircraft owners. It was not possible to make it scan the temptable of aircraft owners and make lookups into people.
WL#3985 fully addresses #1 and #2, and partially addresses #3. That is, now
- Semi-join subqueries can use Materialization in an inner-to-outer fashion
- Join optimizer is aware of existence of semi-joins and makes a fully automatic, cost-based choice between FirstMatch, DuplicateWeedout, LooseScan, inner-to-outer and outer-to-inner variants of Materialization.
This is expected to be a considerable improvement. The most common class of subqueries,
SELECT ... WHERE expr IN (SELECT ... w/o GROUPing/UNIONs/etc) AND ...
is now covered by a reasonably complete set of execution strategies and the optimizer is expected to have the capability to choose a good strategy for every case.
Possible gotchas, and we’re looking for input
I can’t state that the subquery optimizer does have the capability to pick a good plan because we haven’t done much experiments with the subquery cost model yet. We intend to do some benchmarking, but will also very much appreciate any input on how does the subquery optimizer behave for real-world queries. The code should be reasonably stable now – there are only three known problems, all of which are not very popular edge cases:
- LEFT JOINs. You may get wrong query results when the subquery or parent subquery use left joins.
- “Grandparent” correlation. A query with a semi-join child subquery which has a semi-join grandchild subquery which refers to a column in the top-level select may produce wrong query plans/results under certain circumstances.
- Different datatypes. You may get wrong query results of queries that have col1 IN (SELECT col2) where col1 and col2 are of different types (which should not happen too often in practice)
If you have subqueries with LEFT JOINs, please let us know also, because so far all LEFT JOIN+subquery cases we have were generated by the random query generator, certain properties of MySQL codebase make it difficult to make outer joins work with semi-joins, and if we don’t get any real-world LEFT JOIN examples, chances are we will disable subquery optimizations if there’s LEFT JOIN in the parent select, or in the subquery, or in either case.
 <!–
<!–  –>
–>