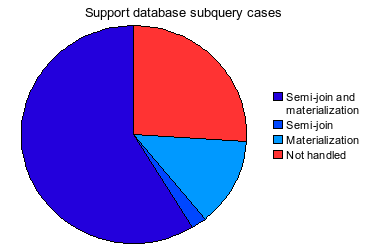
As I wrote earlier, we (me and Ranger) have done an assessment of the impact of new 6.0 subquery optimizations. First, we’ve done a search for performance issues in MySQL’s bug database. The raw list is here, and the here is a summary chart:

Search for customer issues in MySQL’s issue tracker system has produced a similar picture (raw list):
Search in DBT-{1,2,3,4} open source benchmark suites produced a radically different result though (raw data is here):
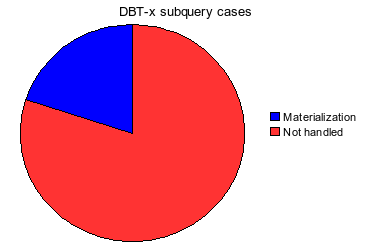
The samples are small but I think one can already conclude that the benchmarks and user cases have different kinds of subqueries. The cause of the discrepancy is not clear. Are people’s applications different from what the benchmarks simulate? If yes, what is the benchmark that simulates the apps our users are running?
A dumb search for subqueries in random open source applications using grep didn’t produce much. Again, no idea why, either I was looking at the wrong applications, or it could be that applications that use subqueries do not have SQL statements embedded in their code so one can’t find them with grep, or something else.
So far the outcome is that it’s nice that the new optimizations [will] capture a good fraction of real world cases, but there is no benchmark we could run to check or demonstrate this. Well, I’d still prefer this situation over the the opposite.

> A dumb search for subqueries in random open source applications using grep didn’t produce much. Again, no idea why,
I tried to use subqueries (like select * from T where F in (select …) but those queries were way too slow to be usable, so I just forgot about subqueries.
LikeLike
Olaf,
So yours are WHERE … IN, too. Good to hear. It seems we’re going to have this class of subqueries covered reasonably well in MySQL 6.0
LikeLike
[…] So the first impression is that MySQL kinda wins this round. But wait, if you look at user subquery case analysis here, you’ll see that the vast majority of semi-join subqueries are uncorrelated. I wonder if PG folks at some point in the past have made a conscious decision not to bother optimizing correlated subqueries. […]
LikeLike
[…] The reason is MySQL Optimizer Team did not have the goal of optimizing TPC-H queries or queries from any other benchmarks, rather they look at the queries which MySQL Users have problem with and first target the most common issues. I think this is a great approach to pick what needs to be done first. […]
LikeLike
The site I’ve developed involves a lot of the following types of query:
SELECT
`s2`.`morestuff`
,`s3`.`extrastuff`
,…
FROM (
SELECT id, morestuff, …
FROM stuff2
INNER JOIN …
) `s2`
LEFT JOIN (
SELECT id, extrastuff, …
FROM stuff3
INNER JOIN …
) `s3`
ON `s3`.`id` = `s2`.`id`
AND `s3`.`xxx` = `s2`.`xxx`
WHERE …
Performance under MySQL is “okay” not great but “okay”, MSSQL just eats these for lunch! Just goes to show how different the two optimisers are!
One question I’ve always pondered is when the optimiser puts the results of subquery into temp table for joining to parent query [when looking at EXPLAIN results] why doesn’t it automagically index the join fields? Surely indexing and optimising on that cheaper than a lumbering scan? Also helps people who think in set theory terms which I thought was the point of RDBMS’s!
In terms of other subqueries, personally I try to avoid using IN clauses at all, neither MySQL or MSSQL likes them.
LikeLike
> One question I’ve always pondered is when the optimiser puts the results of subquery into temp table for joining to parent query [when looking at EXPLAIN results] why doesn’t it automagically index the join fields?
There’s really no good reason, that’s a deficiency in the optimizer. At the moment you might get some speedups by using VIEWs instead of FROM subqueries. Certain VIEWs can be “merged” into the upper query. This doesn’t give auto-indexing, but at least the optimizer is able to use the indexes that exist in the tables that the VIEW refers to.
We’re now trying to address FROM subquery handling, see http://forge.mysql.com/worklog/task.php?id=3485. I can’t yet tell which version this will go in, though.
LikeLike
Thanks for the link, it’s nice to know that these things are in the pipeline! I did look at VIEWs but in my case they didn’t really fit: I think I decided that the volumes would be too large to be efficient.
Although this is slightly off topic, I feel that this is still much work to be done regarding such temporary tables and maybe that’s where the problem ultimately lies. In my opinion such changes like efficient subqueries, indexing temporary tables, joining temporary table to itself etc. should be given priority over “new exotic” functionality.
LikeLike