The work on subquery optimizations goes on, and we’re already curious how the assortment of new 6.0 subquery optimizations compares to what is found in other DBMSes. MySQL’s new strategies are not DBMS theory breakthroughs, similar ideas have been implemented in other DBMSes, but when you take this list of strategies and put them into this kind of optimizer, the result has no direct equivalents in any other DBMS (or at least we believe so).
The first thing we did was to take a look at PostgreSQL as it is easily available and seems to have at least decent subquery handling (or even better than decent, I have not heard much complaints). And the first interesting difference was handling of correlated subqueries. With exception of materialization, MySQL’s new subquery strategies do not care if the subquery is correlated or not.
For example, let’s look at table pullout: First let’s try an uncorrelated subquery:
mysql> explain select * from tbl1 where col1 in (select primary_key from tbl2 where col2 show warnings\G
...
Message: select `test2`.`tbl1`.`col1` AS `col1`,`test2`.`tbl1`.`col2` AS `col2` from (`test2`.`tbl2`) join `test2`.`tbl1`
where ((`test2`.`tbl1`.`col1` = `test2`.`tbl2`.`primary_key`) and (`test2`.`tbl2`.`col2` < 20))
and we see that it has been converted into an inner join (indicated by the part marked in red). Now let’s make the subquery correlated:
mysql> explain select * from tbl1 where col1 in (select primary_key from tbl2 where
-> col2 show warnings\G
...
Message: select `test2`.`tbl1`.`col1` AS `col1`,`test2`.`tbl1`.`col2` AS `col2` from (`test2`.`tbl2`) join `test2`.`tbl1`
where ((`test2`.`tbl2`.`primary_key` = `test2`.`tbl1`.`col1`) and (`test2`.`tbl2`.`col2` = `test2`.`tbl1`.`col2`) and
(`test2`.`tbl1`.`col2` < 20))
The query execution plans are different (because of the extra equality) but we see that subquery was converted into join in both cases.
Now let’s try PostgreSQL: first, uncorrelated subquery:
psergey=# explain select * from tbl1 where col1 in (select primary_key from tbl2 where col2 Index Scan using tbl1_col1 on tbl1 (cost=0.00..56.66 rows=600 width=8)
-> Index Scan using tbl2_pkey on tbl2 (cost=0.00..503.25 rows=12 width=4)
Filter: (col2 < 20)
Ok, a decent plan. Now, let’s make the subquery correlated:
psergey=# explain select * from tbl1 where col1 in (select primary_key from tbl2 where
psergey(# col2 Seq Scan on tbl2 (cost=0.00..200.00 rows=1 width=4)
Filter: ((col2 < 20) AND (col2 = $0))
and we can see that PostgreSQL starts using the “naive” approach, where the subquery predicate is evaluated using a direct, straightforward fashion and is not used for any optimizations.
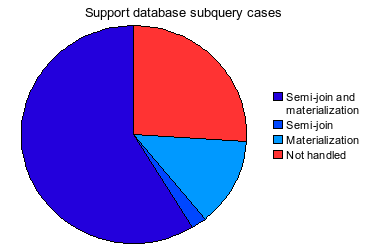
So the first impression is that MySQL kinda wins this round. But wait, if you look at user subquery case analysis here, you’ll see that the vast majority of semi-join subqueries are uncorrelated. I wonder if PG folks at some point in the past have made a conscious decision not to bother optimizing correlated subqueries.
For uncorrelated subqueries, it’s different. Our first impression is that PostgreSQL has a powerful tool – hash join and its subquery variants, which it uses to get decent performance in wide variety of cases. MySQL does not have hash join (Hi Timour? Kaamos?), but the new subquery optimizations can have kinda-similar behavior. It is not clear yet whether they’ll be a good subquery hash join substitute. I intend to post the analysis here once I figure it out. Stay tuned.



 <!–
<!–  –>
–>